AI (人工智能): 服务器
关于
Agent DVR 完全与 AI 服务器集成,如 DeepStack AI、CodeProject AI、PlateRecognizer.com、Claude、Gemini、OpenAI (ChatGPT) 以及本地 LLM,如 Ollama、vLLM 和 LM Studio,以添加智能警报过滤、物体识别、场景识别和智能事件控制。
除了 DeepStack 和 CodeProject AI,您还可以使用其他支持相同 API 的 AI 服务器:
物体识别与计算机视觉
- https://codeproject.github.io/ - 跨平台 GPU/CPU 基于的 AI 处理服务器
- https://docs.platerecognizer.com/ - 车牌识别服务器(基于 Web 的 API)
- https://github.com/runningman84/docker-coral-rest-server - 在 RPi(或 Linux/Mac)上使用 Coral USB 设备加速的 Tensorflow-lite 模型
- https://github.com/robmarkcole/coral-pi-rest-server/ - 通过 Flask 应用程序在 Coral USB 加速器上运行的 Tensorflow-lite 模型
- https://github.com/xnorpx/blue-candle - 超小型物体识别服务器
云 AI 服务
- https://platform.openai.com/ - OpenAI API(ChatGPT、GPT-4 Vision)用于图像分析和聊天
- https://console.anthropic.com/ - Anthropic Claude API 用于高级推理和图像理解
- https://ai.google.dev/ - Google Gemini API 用于多模态 AI 能力
- https://docs.anthropic.com/ - Claude API 文档
- https://platform.openai.com/docs/ - OpenAI API 文档
- https://ai.google.dev/gemini-api/docs - Gemini API 文档
本地 AI 服务器(LLMs)
- https://ollama.com/ - Ollama:本地运行大型语言模型
- https://docs.vllm.ai/ - vLLM:高吞吐量 LLM 推理和服务
- https://lmstudio.ai/ - LM Studio:易于使用的本地 LLM 桌面应用程序
- https://github.com/ollama/ollama - Ollama GitHub 仓库
- https://github.com/vllm-project/vllm - vLLM GitHub 仓库
添加 AI 模型
要将您自己的模型文件添加到 Agent DVR 中,请转到 服务器设置 > AI 设置,然后在 AI 模型 下单击 配置。Agent 附带了两个经过性能调优的预构建模型,专为 Agent DVR 设计。
在配置模型之前,您需要将其添加到 Agent DVR 的模型文件夹中。该文件夹通常位于 Agent/Media/Models/ONNX(路径可能因操作系统而异)。如果您不确定,添加模型页面上会显示完整路径。Agent 使用 .onnx 模型。您可以使用 Python 工具将其他 AI 模型格式转换为 ONNX。
一旦您构建并复制了模型,将其添加到 Agent 中非常简单 - 单击以添加模型:
- 名称: 给您的模型命名 - 这可以是您喜欢的任何名称。
- 模型文件: 选择您复制到文件夹中的模型文件名。
- 标签: 输入您的模型在 CSV 格式中查找的标签(或“类别”)列表,不带引号(空格会自动修剪)。
- 布局: 选择您的模型是 NCHW 还是 NHWC。如果不确定,大多数模型是 NCHW。
- 通道顺序: 选择您的模型希望图像是 RGB 还是 BGR。大多数模型使用 RGB。如果您的模型是单通道(灰度),则此项将被忽略。
- 归一化: 选择数据在用于模型之前应如何归一化。大多数模型使用 0-1 归一化(将像素值除以 255)。
- 填充图像: 这控制图像是否应拉伸到输入尺寸或用黑条填充。通常,为了准确性,最好填充图像。
- 具有 NMS: 如果您的模型已经在内部执行非最大抑制,请勾选此项。否则,Agent 将自行执行 NMS。NMS 控制结果矩形的过滤方式。
- 默认 NMS: 设置 NMS 的重叠限制器(默认是 45% 重叠)。
添加模型后,它将在您设备的 对象识别 选项卡中可用。如果您遇到问题,可以返回模型配置并进行更改。Agent 还支持重新加载模型文件,因此您可以在运行时用新版本覆盖它。
设置 AI 服务器
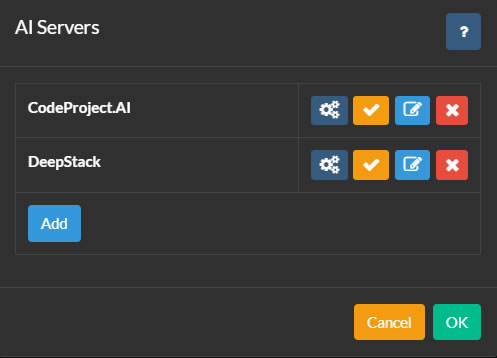
要设置AI服务器,请单击主Agent DVR用户界面左上角的图标。然后在配置下单击设置,从下拉菜单中选择AI设置,并在AI服务器下单击配置。
Agent DVR与CodeProject.AI集成,提供各种AI功能,包括对象识别、人脸识别、ALPR(自动车牌识别)和超分辨率(增强)。PlateRecognizer.com也被支持作为ALPR提供商。CodeProject.AI是开源的,免费且兼容大多数平台。
首先,为您的平台安装AI服务器,并通过单击配置按钮然后添加将Agent DVR连接到它。
您可以根据需要向Agent DVR添加多个AI服务器。Agent DVR中的摄像头可以配置为为每个功能使用不同的AI服务器,或者您可以为所有任务使用一个AI服务器。
配置您的服务器
- 名称:为您的服务器命名,例如,猫捕手。
- AI服务器URL:输入您的AI服务器的URL,例如,http://localhost:32168/
- API密钥:如果已设置,请输入您的密钥(可选)。
- 超时:服务器请求的超时时间(以秒为单位)。
- 重试延迟:在重试对该服务器的失败请求之前的时间(以秒为单位)。
单击确定以保存您的设置。
使用OpenAI
要设置OpenAI("Chat GPT")来回答有关视频源中发生的事情的问题,请导航至服务器设置 - AI服务器 并在"询问AI"下选择"Open AI"。
- URL: 输入服务的URL。默认为"https://api.openai.com/v1/chat/completions"。
- OpenAI API密钥: 在OpenAI注册后,转到API密钥页面 并生成一个新的秘密密钥。将此密钥复制并粘贴到指定字段中。
- 模型: 指定要使用的模型。默认为gpt-4o。OpenAI可能会在以后删除或更改此模型。
- 最大令牌数: 设置每个请求的最大令牌使用量。如果遇到问题,请检查/logs.html中的日志,因为这可能与令牌使用有关。
一旦配置了OpenAI,请参考询问AI以获取有关如何将其用于回答有关摄像头视频源中发生的事情的一般问题的说明。
使用云端
To set up Claude AI to answer questions about what's happening in your video feed, navigate to Server Settings - AI Servers and select "Claude" under Ask AI.
- URL: Enter the URL to the service. Default is "https://api.anthropic.com/v1/messages".
- Claude API Key: After signing up for Claude, visit the API Keys Page and create a new secret key. Copy and Paste this key into the field.
- Version: Specify the version to use. The default is 2023-06-01 This may be removed or changed at some point by Anthropic.
- Model: Specify the model to use. The default at time of writing is claude-3-sonnet-20240229.
- Max Tokens: This controls the maximum token spend per request. Check the logs at /logs.html if you have issues as it might be related to token spend.
Once Claude is configured see Ask AI for how to use it to recognise general scenarios in your camera feed.
使用Gemini
要设置Gemini来回答有关视频源中发生的情况的问题,请导航至服务器设置 - AI服务器 并在“询问AI”下选择“Gemini”。
- URL: 输入服务的URL。默认为"https://generativelanguage.googleapis.com"。
- Gemini API密钥: 注册Gemini后,请访问API密钥页面并创建一个新的秘密密钥。将此密钥复制并粘贴到字段中。
- 版本: 指定要使用的版本。默认为v1beta。这可能会被Google在某些时候移除或更改。
- 模型: 指定要使用的模型。撰写时的默认值为gemini-1.5-flash。
- 最大令牌数: 这控制每个请求的最大令牌消耗。如果遇到问题,请检查/logs.html中的日志,因为问题可能与令牌消耗有关。
一旦配置了Gemini,请查看询问AI,了解如何使用它来识别摄像头源中的一般情景。
使用其他LLM服务器
从 v6.5.3.0+ 开始,您可以使用自己的本地 LLM 服务器(如 vLLM、Ollama 和 LM Studio)来描述 Agent DVR 从您的摄像头捕获的图像在警报事件中,并回答有关您视频流中发生的事情的问题。请参见 AI 描述 和 询问 AI。
要配置本地 AI 服务器,请转到服务器设置 - AI 服务器,然后单击您要使用的 LLM 旁边的配置按钮(Ollama、vLLM 或 LM Studio)。
- URL: 指定您的 LLM 服务器正在运行的端点。默认 URL 为:
- Ollama:
http://localhost:11434/api/chat - vLLM:
http://localhost:8000/v1/chat/completions - LM Studio:
http://localhost:1234/v1/chat/completions
- Ollama:
- API 密钥: 如果您的 LLM 服务器需要身份验证,请在此处输入 API 密钥。大多数本地服务器不需要此项,除非特别配置。
- 模型: 选择用于图像分析的视觉能力模型。您必须已经在 LLM 服务器中下载并加载此模型。常见选择包括:
- LLaVA 模型(通用视觉)
- Qwen2-VL(高性能)
- Llama 3.2 Vision(Meta 最新款)
- 温度: 控制响应中的创造力与准确性(0.0-1.0)。较低的值(0.3-0.4)产生更事实、连贯的描述。较高的值(0.6-0.8)生成更丰富、多样的响应。推荐:安全摄像头分析使用 0.4。
- 最大标记数: AI 响应中的最大单词/标记数。较高的值允许更详细的描述,但生成时间更长。推荐:详细图像分析使用 300-500,简短描述使用 150-250。
- top_p: 通过限制词汇选择来控制响应多样性(0.0-1.0)。较低的值使用更常见的单词,较高的值允许更多样的词汇。推荐:0.9,以获得准确性和自然语言的良好平衡。
- top_k: 限制模型从最可能的下一个单词中选择前 K 个。较低的值(20-40)产生更集中的响应,较高的值(80-100)允许更多变体。推荐:50,以获得可靠的图像描述。
使用PlateRecognizer.com
要在Agent DVR中配置LPR(ANPR或车牌识别),请转到服务器设置 - AI设置,并在车牌识别器下输入详细信息。在Plate Recognizer上注册免费试用。无需信用卡。
使用 DoubleTake
DoubleTake是一个开源平台,提供统一的API用于处理面部识别,使用:
- CompreFace
- Amazon Rekognition
- DeepStack
- CodeProject.AI Server
- Facebox
您需要安装并配置DoubleTake,并选择您偏好的面部识别选项。
一旦设置好DoubleTake,打开Agent DVR,进入服务器设置 - AI Servers,然后点击DoubleTake旁边的配置按钮。
输入您的doubletake服务器的URL(例如:http://localhost:3000/)以及您的密码(如果已设置)。
点击确定,然后编辑一个摄像头,进入面部识别。将AI服务器选项设置为DoubleTake,并根据需要配置面部识别。
管理AI模块
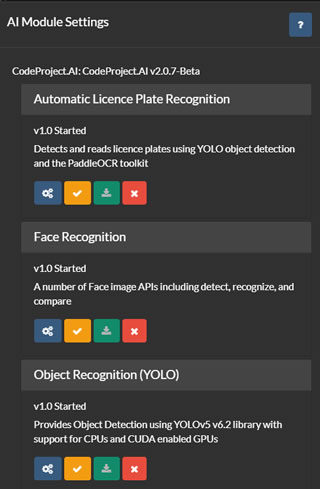
在上面提到的AI服务器列表中,您可以选择配置、测试、编辑和删除AI服务器。单击配置按钮以显示所选服务器上可用或已安装的模块。
Agent DVR从您的服务器检索当前模块列表,并提供用户界面以安装、卸载、配置和测试每个模块。对于所有默认的CodeProject.UI模块都提供支持,尽管Agent DVR仅使用其中的一部分。
要在Agent DVR中使用车牌自动识别(ALPR)、超分辨率或人脸识别,您需要从此页面安装相应的模块。通常情况下,这些模块的默认设置就足够了,但您可以通过单击每个模块下的图标来进行配置。