AI (人工智慧): 配置
本地物體識別
Agent DVR 支援使用 AI 模型檔 (.onnx) 進行即時實時物體識別。您需要一個 許可證(或有效訂閱)才能使用此功能。請參閱 AI 伺服器 以配置 Agent 使用外部 AI 伺服器。
要開始使用,編輯您的攝影機並轉到 物體識別 標籤。選擇您在頂部的 AI 伺服器。默認為 內部,這是 Agent DVR 的內建 AI。如果您想使用 AI 伺服器,請在伺服器設置 - AI 設置 - AI 伺服器中添加它,然後在這裡選擇。
以下詳細信息是用於配置 Agent DVR 及其快速內建 AI。您也可以添加任何其他模型,例如 Ultralytics YOLO 模型。
- 模型: 選擇您想使用的 AI 模型。Agent 將根據需要自動下載內建模型。Tiny 模型適合低端硬體或大量攝影機。Medium 模型適合更好的準確性,但需要更多的處理能力。
- 模式: 選擇您希望 AI 何時處理視頻幀。如果您選擇 間隔,Agent 將使用下面的 處理速率 欄位持續分析您的視頻流。
- 覆蓋: 勾選以在實時視頻上繪製實時結果。這對於調整信心限制非常有用。
- 模糊: 勾選此項以模糊識別的物體(例如,人)。
- 使用 GPU: 勾選此項以使用您的 GPU 而不是 CPU。
- 處理速率: 這僅在 模式 為 間隔 時使用 - 它控制發送幀到模型的速率。輸入 1 表示每秒 1 幀,20 表示每秒 20 幀或 0.1 表示每 10 秒 1 幀。
- 信心: 這過濾模型的結果。將此值調高以減少誤報,但請注意,它也可能會漏掉物體。
- 檢查角落: 有關更多詳細信息,請參閱 檢查角落。
- 查找: 指定 AI 要檢測的物體。這裡的選項列表來自模型配置。
- 忽略靜態物體: 忽略在同一位置重複發現的物體。
- 容差: 這控制物體在被標記為非靜態之前可以移動的範圍。
自定義模型
要將自己的模型添加到 AI,請將模型檔 (.onnx) 複製到 Agent 的模型資料夾中,並參見 添加模型。
操作
物體識別會生成 AI: 找到物體 和 AI: 未找到物體 事件以用於 操作。
照片
有關照片的信息,請參見 照片。
將 Ultralytics YOLO 模型轉換為 ONNX
Agent DVR 支援 ONNX 模型檔案以進行物件識別。您可以下載預訓練模型並在幾個步驟中將其轉換為 ONNX 格式。
以下範例使用 Ultralytics 的 YOLO26s 模型。YOLO26s 是一個較小的通用模型,具有良好的速度/準確性平衡。
前提條件
- Python 3.10 或更新版本
- pip 可在 PATH 中使用
- 需要網際網路連接
- 約 1–2 GB 的可用磁碟空間
步驟 1 – 安裝 Ultralytics
pip install ultralytics步驟 2 – 下載 YOLO26s 模型
Ultralytics 在首次使用時會自動下載預訓練權重:
yolo detect predict model=yolo26s.pt source=https://ultralytics.com/images/bus.jpg步驟 3 – 轉換為 ONNX
下載後,將模型導出為 ONNX 格式:
yolo export model=yolo26s.pt format=onnx opset=12 simplify=TruePython 替代方案
from ultralytics import YOLO
model = YOLO("yolo26s.pt")
model.export(format="onnx", opset=12, simplify=True)步驟 4 – 找到 ONNX 檔案
導出的
yolo26s.onnxruns/export步驟 5 – 複製到 Agent DVR
將 ONNX 檔案移動到您的 Agent DVR ONNX 模型資料夾(在 Agent 伺服器上),例如:
Agent\Media\Models\ONNX\步驟 6 – 在 Agent DVR 中添加模型
- 前往 伺服器設定 > AI 設定 > AI 模型。
- 點擊 配置 並添加新模型。
-
輸入名稱(例如
)並在下拉選單中選擇yolo26s
檔案。.onnx - 將其餘選項保持為預設值,然後點擊 確定。
- 編輯您的攝影機,打開 物件識別 標籤,將 伺服器 設定為 內部,並選擇您的新模型。
本地人臉識別
Agent DVR 支援使用 AI 進行即時實時臉部識別。您需要一個許可證(或有效訂閱)才能使用此功能。請參閱AI 伺服器以配置 Agent 使用外部 AI 伺服器。
要開始使用,編輯您的攝影機並轉到臉部識別標籤。在頂部選擇您的 AI 伺服器。默認為內部,即 Agent DVR 的內建 AI。如果您想使用 AI 伺服器,請在伺服器設置 - AI 設置 - AI 伺服器中添加它,然後在這裡選擇。
以下詳細信息是用於配置 Agent DVR 以使用其快速內建 AI。
- 模式:選擇您希望 AI 處理視頻幀的時間。如果您選擇間隔,Agent 將使用下面的處理速率字段持續分析您的視頻流。
- 覆蓋:勾選以在實時視頻上繪製即時結果。這對於調整信心限制非常有用。
- 模糊:勾選此項以模糊面孔。
- 使用 GPU:勾選此項以使用您的 GPU 而不是 CPU。
- 處理速率:這僅在模式為間隔時使用 - 它控制幀發送到模型的速率。輸入 1 表示每秒 1 幀,20 表示每秒 20 幀,或 0.1 表示每 10 秒 1 幀。
- 信心:這過濾模型的結果。將此值調高以減少誤報,但請注意,它也可能會漏掉人。
- 檢查角落:有關更多詳細信息,請參閱檢查角落。
要識別的面孔
點擊編輯面孔以上傳您想要識別的人的照片。您可以上傳同一人的多張照片以改善結果。您可以從文件系統上傳圖像或使用內建的網絡攝像頭捕捉照片(需要 SSL 或本地主機)。
操作
臉部識別生成AI:已識別面孔和AI:未識別面孔事件以用於操作。
照片
有關照片的信息,請參見照片。
本地車牌識別
Agent DVR 支援即時實時車牌識別。您需要一個授權(或有效訂閱)來使用此功能。請參閱AI 伺服器以配置 Agent 使用外部 AI 伺服器。
要開始使用,編輯您的攝影機並轉到LPR標籤。在頂部選擇您的 AI 伺服器。默認為內部,這是 Agent DVR 的內建 AI。如果您想使用 AI 伺服器,請在伺服器設置 - AI 設置 - AI 伺服器中添加它,然後在這裡選擇。
以下詳細信息用於配置 Agent DVR 與其快速內建 AI。
- 模式:選擇您希望 AI 處理視頻幀的時間。如果您選擇間隔,Agent 將使用下面的處理速率字段持續分析您的視頻流。
- 疊加:勾選以在實時視頻上繪製實時結果。這對於調整信心限制非常有用。
- 模糊:勾選此項以模糊檢測到的車牌。
- 使用 GPU:勾選此項以使用您的 GPU 而不是 CPU。請注意,這目前僅在 Windows 或 macOS 上有效,因為 GPU 驅動程序和運行時支持。Linux 目前回退到 CPU。
- 處理速率:這僅在模式為間隔時使用 - 它控制發送幀到模型的速率。輸入 1 表示每秒 1 幀,20 表示每秒 20 幀,或 0.1 表示每 10 秒 1 幀。
- 信心:這過濾模型的結果。將此值調高以減少誤報,但請注意,它也可能會漏掉物體。
- 檢查角落:有關更多詳細信息,請參閱檢查角落。
要查找的車牌
- 車牌:輸入以逗號分隔的車牌列表或包含車牌的 CSV 文件的 URL。Agent DVR 將為這些車牌生成車牌識別和車牌未識別事件,這些事件可以觸發操作。
- 重新加載間隔:設置從 URL 重新加載車牌列表的頻率。
- 標準化:調整常見的誤識別車牌以改善匹配。
操作
物體識別生成AI:車牌識別和AI:車牌未識別事件以用於操作。
照片
有關照片的信息,請參閱照片。
AI 警報過濾
要在 Agent DVR 中設置警報過濾,請按照以下步驟操作:
- 配置並啟用運動檢測器。為了最小化 CPU 使用率,請使用簡單檢測器。確保至少定義一個區域以覆蓋您想要監控的區域。
- 在警報標籤上,將模式設置為僅動作並啟用警報。
- 在錄影標籤上,將模式設置為警報(如果您想要錄影)
- 在物體識別標籤上啟用物體識別。將模式設置為檢測到運動,選擇一個模型,然後單擊查找以選擇要檢測的物體,例如人、狗、車等。
- 在標籤菜單中轉到動作並為事件AI: 找到物體添加一個動作。
選擇區域以指定檢測物體的位置,例如為您的車道和道路選擇不同的區域。例如,選擇車道區域僅在檢測到車輛時觸發警報。
在任務下,單擊添加以創建一個警報任務。單擊確定兩次以確認。
Agent DVR 將在檢測到運動時處理 AI 物件識別。如果它在選定區域內檢測到指定物件,將觸發動作以發出警報。如果未選擇區域,則將對任何區域觸發警報。
類似地為 LPR 識別、人臉識別 或 音頻識別 設置警報過濾器。
要在沒有運動檢測觸發的情況下進行持續的 AI 物件識別,請將物件識別的 模式 設置為 間隔。監控對硬體資源的影響並根據需要進行調整。
您可以為不同區域中的不同物件配置多個動作。在動作中使用 {AI} 標籤來引用檢測到的物件。
AI 過濾器故障排除
如果AI無法有效地過濾您的錄像,請考慮以下事項:
- 確保尋找設置與可用選項之一相符。
- 驗證Agent左上角的主警報開關是否顯示一個關閉的掛鎖,表示活動警報。
- 確認錄像模式設置為警報而不是檢測。
- 確保警報模式設置為僅限操作。
- 嘗試降低物體識別下的信心水平。
- 檢查/logs.html以查看錯誤消息,可能指示服務器問題或網絡阻塞。
- 監控AI服務器性能,確保不會導致系統超載或超時。
- 如果AI檢測到所有物體類別,可能表示GPU問題。請檢查GPU驅動程序或切換到基於CPU的AI模塊。
AI物件識別
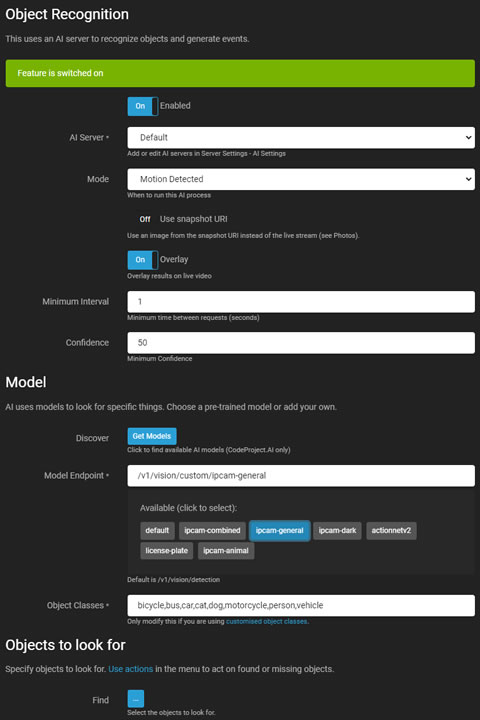
Agent DVR 中的物件識別使用我們的 本地 AI 或 AI 伺服器(建議使用 CodeProject.AI)來識別視頻流中的特定物件,並可以生成事件、發出警報或作為 運動警報的過濾器。
- 啟用: 切換以啟用或禁用 AI 處理。
- AI 伺服器: 從您配置的 伺服器 中選擇,或使用預設選項。
- 模式: 選擇 AI 處理的觸發器。僅通過將此設置為無來通過 API 觸發,並調用 triggerObject。
- 運動通過: 如果 AI 伺服器關閉並過濾警報,則允許警報不經過濾而通過。
- 使用快照 URI: 使用來自攝像頭的高解析度幀,而不是當前的實時流幀。
- 調整大小模式: 在將圖像發送到 AI 伺服器之前調整圖像大小,以減少負載並改善響應時間。
- 疊加: 在實時視頻流上顯示 AI 結果。
- 顏色: 疊加的顏色。此設置控制所有 AI 功能的疊加顏色。
- 最小間隔: 設定伺服器請求之間的最小時間。
- 信心: 設定識別物件的最小信心水平。
- 檢查角落: 有關更多詳細信息,請參閱 檢查角落。
模型
- 發現: 從您的伺服器檢索已安裝的模型(特定於 CodeProject.AI)。
- 模型端點: 從可用模型中選擇或使用默認端點。
- 物件類別: 自動填充相關類別或手動輸入。
- 查找: 指定 AI 檢測的物件。
- 忽略靜態物件: 忽略在同一位置重複發現的物件。
自訂模型
要將自訂模型添加到 CodeProject.AI,請將模型檔案複製到指定目錄。通過發現按鈕訪問,但需手動將物件列表添加到 物件類別。
通過編輯物件識別模組的設置來更改模型儲存的目錄。
操作
物件識別會生成 AI: 找到物件 和 AI: 未找到物件 事件以供 操作 使用。
照片
有關照片的信息,請參見 照片。
請求 AI
Agent DVR 使用 AI 伺服器(OpenAI/ Claude 等)來回答關於您攝影機圖像的人類可讀問題。這樣可以生成事件、發出警報,或者作為運動警報的過濾器。您需要在伺服器設置 - AI 伺服器 - 詢問 AI 中完成設置。
您可以在本地伺服器的 /logs.html 上檢查日誌,查看何時發送請求。將伺服器設置 - 日誌記錄 - 日誌級別設置為 Info。
- 已啟用: 切換以啟用或停用 AI 處理。
- 提供商: 選擇要用於處理圖像的 AI 提供商。提供商需要在伺服器設置 - AI 伺服器中進行配置。如果選擇默認,則將使用第一個配置的提供商。
- 模式: 選擇 AI 處理的觸發器。通過將其設置為 None 並調用triggerAskAI僅通過 API 觸發。
- 運動通過: 如果 AI 伺服器關閉並過濾警報,則允許警報無需過濾即可通過。
- 使用快照 URI: 使用攝影機的高分辨率幀,而不是當前的實時串流幀。
- 調整大小模式: 在將圖像發送到 AI 伺服器之前調整大小,以減輕負載並改善響應時間。
- 覆蓋: 在實時視頻流上顯示 AI 結果。
- 最小間隔: 設置伺服器請求之間的最小時間。
AI 消息
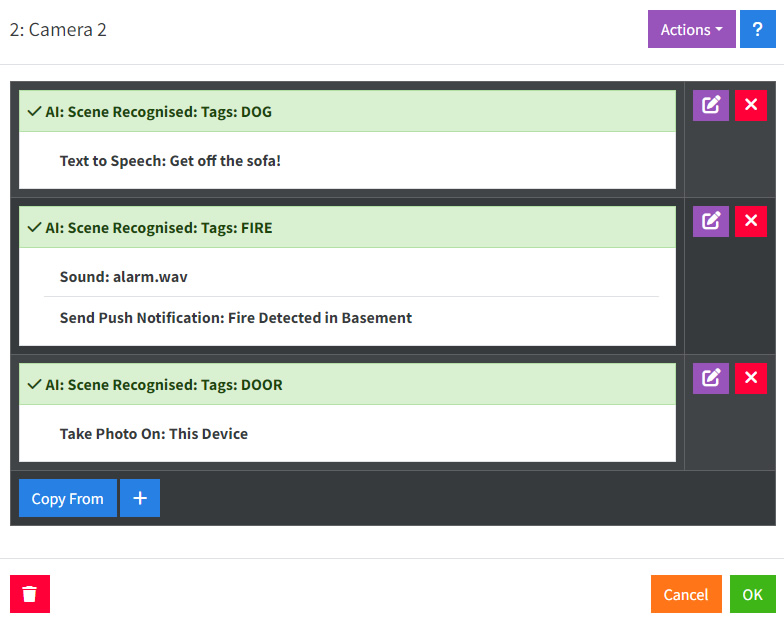
- 消息:在這裡輸入您對 AI 的問題。一些例子:
- 如果您在這張圖片中看到火災,請回答 FIRE。如果您看到一隻狗坐在沙發上,請回答 DOG。如果門是開著的,請回答 DOOR。如果滿足多個條件,請用逗號分隔它們。
- 如果機器上的燈是紅色的,請回答 ALERT
- 如果有警車停在車道上,請回答 POLICE
- 如果地板上有信件或包裹,請回答 MAIL
- 如果看起來有人闖入我的房子,請回答 BREAKIN
- 尋找:輸入您已指示 AI 回答的標籤。例如 FIRE、DOG、DOOR
- 不重複:忽略上次呼叫 AI 時返回的標籤
如上所述,您可以要求消息中滿足多個條件,並設置處理每個結果的操作。
操作
場景識別生成 請求 AI:正面結果 事件,供在 操作 中使用。
照片
有關照片的資訊,請參見 照片。請注意,AI 尚未返回有關圖像中事物位置的空間數據,因此裁剪和靜態檢測目前無法正常工作。
AI照片
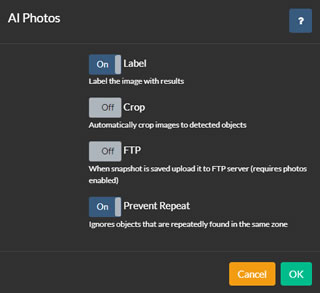
當識別到物體時,AI處理可以捕捉照片,提供保存、裁剪、FTP上傳等選項。
要進行配置,請在編輯攝像機時,轉到每個AI配置選項卡的底部的照片選項。啟用照片並點擊進行配置。
- 標籤:Agent在圖像上覆蓋方框並標註檢測到的物體。
- 裁剪:Agent將圖像裁剪到每個檢測到的區域並保存多個圖像,每個區域一個。
- FTP:將保存的圖像上傳到攝像機配置的FTP服務器。
- 防止重複:Agent避免保存同一物體的多個副本,直到它離開運動區域。
請求 AI:描述
從 v5.8.2.0+ 開始,您可以使用人工智慧來描述 Agent DVR 從攝像機捕捉到的警報事件中的圖像。這個描述將與警報一起存儲在用戶界面中。要設置這個功能,請為您的攝像機配置 Ask AI,然後在 描述 選項下方查看。
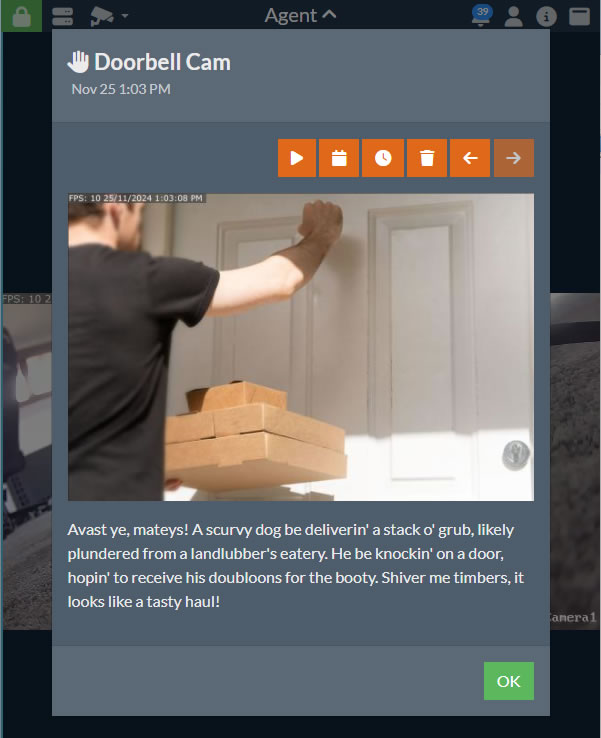
- 提示: 輸入要與圖像一起發送到 AI 伺服器的提示。默認為 "描述這張圖像中正在發生的事情"。您也可以玩得開心一點,例如 "用海盜語言描述正在發生的事情",就像我們在上面的圖像中使用的那樣。
- 接下來,轉到 警報 選項卡,並勾選 描述 選項。
請注意,您需要啟用 Ask AI。如果您只想讓它描述警報圖像,請將 模式 設置為 None。
一旦它開始為您的圖像做註釋,您可以將其與 操作 系統集成,以進行 AI: 描述回應已收到。您可以在此操作的任務中使用 {MESSAGE} 和 {AIJSON} 進行其他集成。
LPR 或 ALPR
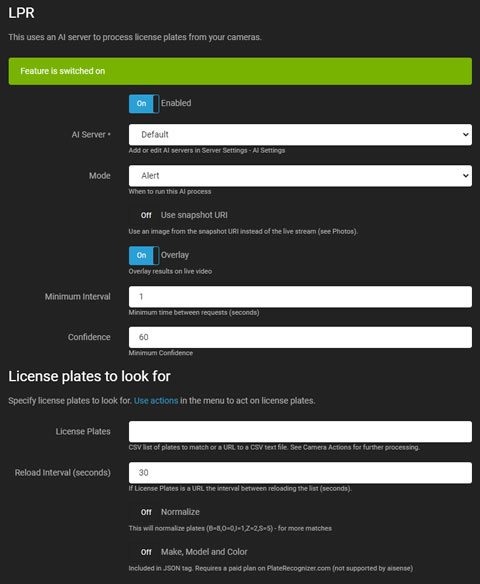
LPR(車牌識別,亦稱為 ALPR/ANPR)利用 AI 伺服器從您的視頻流中識別和讀取車牌。它會生成事件、發出警報,或作為運動警報的過濾器。
- 啟用: 切換以啟用或禁用 AI 處理。
- AI 伺服器: 從您配置的 伺服器 中選擇或使用默認選項。Agent DVR 支持通過 CodeProject.AI、PlateRecognizer.com、Gemini 或任何與 OpenAI 兼容的視覺 LLM(如 vLLM、Ollama 和 LM Studio)進行 LPR。
- 模式: 選擇 AI 處理的觸發器。僅通過 API 觸發,將其設置為無並調用 triggerLPR。
- 使用快照 URI: 選擇來自您的攝像頭的高分辨率幀,而不是當前的實時流幀。
- 疊加: 將 AI 結果疊加到實時視頻流上。
- 最小間隔: 設置伺服器請求之間的最小時間以減少負載。
- 信心: 定義識別車牌的最小信心水平。
- 檢查角落: 有關更多詳細信息,請參閱 檢查角落。
- 車牌: 輸入以逗號分隔的車牌列表或包含車牌的 CSV 文件的 URL。Agent DVR 將為這些車牌生成 已識別車牌 和 未識別車牌 事件,這些事件可以觸發動作。
- 重新加載間隔: 設置從 URL 重新加載車牌列表的頻率。
- 標準化: 調整常見的誤識別車牌以改善匹配。
- 品牌、型號和顏色: 僅在使用支持這些功能的 PlateRecognizer.com 收費計劃時啟用此項。這在免費計劃中不包含。詳細信息將包含在 Agent DVR 操作的 {AIJSON} 中。
操作
LPR 生成 AI: 車牌識別 和 AI: 車牌未識別 事件以用於 操作。
照片
有關照片的信息,請參見 照片。
使用 ALPR-Database
您可以與 ALPR-Database.com 設置集成以存儲您的車牌。請參閱 Agent DVR 與 ALPR-Database 獲取說明。
AI 人臉識別
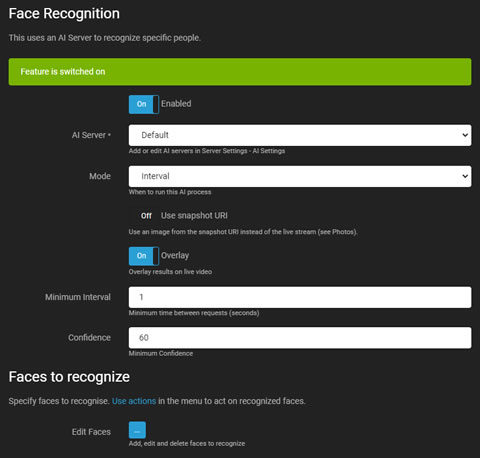
人臉識別利用 AI 伺服器(推薦:CodeProject.AI)來識別視頻流中的特定人臉。它可以生成事件、發出警報,或作為 運動警報的過濾器。可以通過您的攝像頭或上傳圖像來添加、編輯或刪除人臉。請參見本標籤中的 編輯人臉 以獲取更多信息。
- 啟用: 切換以啟用或禁用 AI 處理。
- AI 伺服器: 從您配置的 伺服器 中選擇,或使用默認選項。
- 模式: 選擇 AI 處理的觸發器。僅通過將其設置為無來通過 API 觸發,並調用 triggerFace
- 使用快照 URI: 選擇來自您的攝像頭的高解析度幀,而不是當前的實時流幀。
- 覆蓋: 將 AI 結果覆蓋到實時視頻流上。
- 最小間隔: 設置伺服器請求之間的最小時間以減少負載。
- 信心: 定義識別人臉的最小信心水平。
- 檢查角落: 有關詳細信息,請參見 檢查角落。
- 編輯人臉: 將圖像上傳到伺服器數據庫以進行識別。確保每張圖像中僅顯示一個人臉,並且清晰可見。
操作
人臉識別生成 AI: 人臉識別 和 AI: 人臉未識別 事件以用於 操作。
照片
有關照片的信息,請參見 照片。
AI音訊辨識
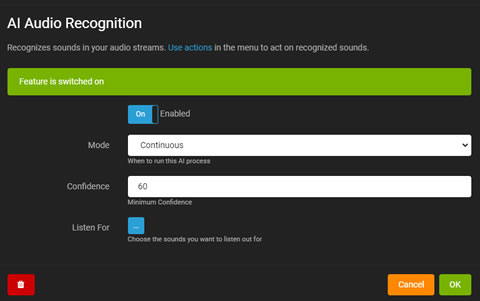
Agent DVR 中基於 AI 的音訊辨識可對來自麥克風或音訊串流的聲音做出反應。請從伺服器設定 - 資料 - AI 音訊模型(需要 iSpyConnect.com 帳戶)下載模型檔案以進行設定。
您需要編輯麥克風設定以設置音訊辨識。如果您有一個帶有音訊串流的攝像機,您可以通過編輯攝像機並選擇音訊標籤,然後點擊“配置”來訪問音訊設定。
- 啟用:切換以啟用或禁用 AI 處理。
- 模式:選擇 AI 處理的觸發方式。
- 信心:設定聲音辨識的最低信心水平。
- 覆蓋:在實時音訊可視化上顯示 AI 結果。
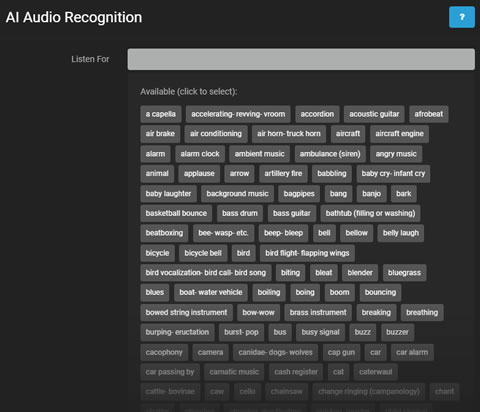
- 監聽:選擇 AI 要檢測的特定聲音。
點擊監聽可顯示可用的檢測聲音。根據需要選擇聲音。
使用動作 AI:音訊辨識來在識別到聲音時執行任務。
音訊辨識也可用於過濾警報,與攝像機類似。
將動作添加至AI事件
Agent DVR 通過 AI 過程生成事件,可以觸發操作。例如,物體識別生成「找到物體」和「未找到物體」的事件。Agent 中的每個 AI 系統都會產生獨特的事件。
這些事件可以觸發各種操作,例如發出警報、使用物體標籤調用 URL、執行程序或將消息發佈到 MQTT 服務器。在操作中使用標籤 {AI} 來標記或使用標籤 {AIJSON} 來獲取 CodeProject.AI 的完整 JSON 響應。