AI: Server
Informazioni
Agent DVR si integra completamente con server AI come DeepStack AI, CodeProject AI, PlateRecognizer.com, Claude, Gemini, OpenAI (ChatGPT) e LLM locali come Ollama, vLLM e LM Studio per aggiungere filtraggio intelligente degli avvisi, riconoscimento degli oggetti, riconoscimento delle scene e controllo intelligente degli eventi.
Oltre a DeepStack e CodeProject AI, puoi utilizzare anche altri server AI che supportano la stessa API:
Riconoscimento degli Oggetti & Visione Artificiale
- https://codeproject.github.io/ - Server di elaborazione AI basato su GPU/CPU multipiattaforma
- https://docs.platerecognizer.com/ - Server di riconoscimento delle targhe (API basata sul web)
- https://github.com/runningman84/docker-coral-rest-server - Modelli Tensorflow-lite su un RPi (o Linux/Mac) con accelerazione da stick USB Coral
- https://github.com/robmarkcole/coral-pi-rest-server/ - Modelli Tensorflow-lite su un acceleratore USB Coral tramite un'app Flask
- https://github.com/xnorpx/blue-candle - Server di riconoscimento degli oggetti super piccolo
Servizi AI Cloud
- https://platform.openai.com/ - API OpenAI (ChatGPT, GPT-4 Vision) per analisi delle immagini e chat
- https://console.anthropic.com/ - API Anthropic Claude per ragionamento avanzato e comprensione delle immagini
- https://ai.google.dev/ - API Google Gemini per capacità AI multimodali
- https://docs.anthropic.com/ - Documentazione API Claude
- https://platform.openai.com/docs/ - Documentazione API OpenAI
- https://ai.google.dev/gemini-api/docs - Documentazione API Gemini
Server AI Locali (LLMs)
- https://ollama.com/ - Ollama: Esegui modelli di linguaggio di grandi dimensioni localmente
- https://docs.vllm.ai/ - vLLM: Inferenza e servizio LLM ad alta capacità
- https://lmstudio.ai/ - LM Studio: App desktop facile da usare per LLM locali
- https://github.com/ollama/ollama - Repository GitHub di Ollama
- https://github.com/vllm-project/vllm - Repository GitHub di vLLM
Aggiunta di modelli AI
Per aggiungere i tuoi file modello in Agent DVR, vai su Impostazioni Server > Impostazioni AI e fai clic su Configura sotto Modelli AI. Agent viene fornito con due modelli predefiniti che sono stati ottimizzati per le prestazioni di Agent DVR.
Prima di configurare un modello, dovrai aggiungerlo alla cartella Modelli di Agent DVR. Questa si trova di solito in Agent/Media/Models/ONNX (il percorso può variare a seconda del sistema operativo). Il percorso completo è visualizzato nella pagina Aggiungi Modello se non sei sicuro. Agent utilizza modelli .onnx. Puoi convertire altri formati di modelli AI in ONNX utilizzando strumenti Python.
Una volta che hai costruito e copiato il modello, aggiungerlo ad Agent è facile: fai clic per aggiungere un modello:
- Nome: Dai un nome al tuo modello - può essere qualsiasi cosa tu voglia.
- File Modello: Seleziona il nome del file del modello che hai copiato nella cartella.
- Etichette: Inserisci un elenco di etichette (o "classi") che il tuo modello cerca in formato CSV senza virgolette (gli spazi vengono automaticamente rimossi).
- Layout: Seleziona se il tuo modello è NCHW o NHWC. La maggior parte dei modelli è NCHW se non sei sicuro.
- Ordine Canale: Seleziona se il tuo modello desidera immagini in RGB o BGR. La maggior parte dei modelli utilizza RGB. Se il tuo modello è a canale singolo (in scala di grigi), questo verrà ignorato.
- Normalizza: Seleziona come i dati devono essere normalizzati prima di essere utilizzati nel tuo modello. La maggior parte dei modelli utilizza la normalizzazione 0-1 (dividi i valori dei pixel per 255).
- Immagine Padding: Questo controlla se l'immagine deve essere allungata alle dimensioni di input o riempita con barre nere. Di solito è meglio riempire le immagini per maggiore precisione.
- Ha NMS: Seleziona questa opzione se il tuo modello esegue già la Soppressione Non Massima internamente. Altrimenti, Agent eseguirà NMS autonomamente. NMS controlla come vengono filtrati i rettangoli dei risultati.
- NMS Predefinito: Imposta il limitatore di sovrapposizione per NMS (il predefinito è il 45% di sovrapposizione).
Una volta aggiunto il tuo modello, sarà disponibile per l'uso nella scheda Riconoscimento Oggetti del tuo dispositivo. Se hai problemi, puoi tornare alla configurazione del modello e apportare modifiche. Agent supporta anche il ricaricamento del file modello, quindi puoi sovrascriverlo con una nuova versione mentre è in esecuzione.
Impostazione dei server AI
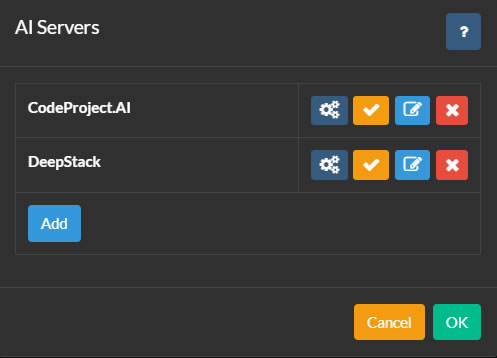
Per configurare i server AI, fai clic sull'icona nell'angolo in alto a sinistra dell'interfaccia principale di Agent DVR. Quindi fai clic su Impostazioni sotto Configurazione, seleziona Impostazioni AI dal menu a discesa e fai clic su Configura sotto Server AI.
Agent DVR si integra con CodeProject.AI per varie funzionalità AI tra cui riconoscimento degli oggetti, riconoscimento facciale, ALPR (Riconoscimento Automatico delle Targhe) e super risoluzione (miglioramento). PlateRecognizer.com è anche supportato come fornitore ALPR. CodeProject.AI è open source, gratuito e compatibile con la maggior parte delle piattaforme.
Per iniziare, installa un server AI per la tua piattaforma e collega Agent DVR ad esso facendo clic sul pulsante Configura e poi Aggiungi.
Puoi aggiungere quanti più server AI a Agent DVR come necessario. Le telecamere in Agent DVR possono essere configurate per utilizzare server AI diversi per ogni funzione, oppure puoi utilizzare un server AI per tutti i compiti.
Configurazione del tuo Server
- Nome: Dai un nome al tuo server, ad esempio, Cattura Gatti.
- URL Server AI: Inserisci l'URL del tuo server AI, ad esempio, http://localhost:32168/
- API Key: Inserisci la tua chiave se impostata (opzionale).
- Timeout: Il timeout in secondi per le richieste al server.
- Ritardo di ripetizione: Il tempo in secondi prima di riprovare una richiesta fallita a questo server.
Fai clic su OK per salvare le tue impostazioni.
Utilizzando OpenAI
Per configurare OpenAI ("Chat GPT") per rispondere alle domande su ciò che sta accadendo nel tuo feed video, vai su Impostazioni Server - Server AI e seleziona "Open AI" sotto Chiedi ad AI.
- URL: Inserisci l'URL del servizio. Il valore predefinito è "https://api.openai.com/v1/chat/completions".
- Chiave API OpenAI: Dopo esserti registrato su OpenAI, vai alla Pagina Chiavi API e genera una nuova chiave segreta. Copia e incolla questa chiave nel campo specificato.
- Modello: Specifica il modello da utilizzare. Il valore predefinito è gpt-4o. OpenAI potrebbe rimuovere o modificare questo in un secondo momento.
- Token Massimi: Imposta l'uso massimo di token per richiesta. Se riscontri problemi, controlla i log su /logs.html poiché potrebbero essere legati all'uso dei token.
Una volta configurato OpenAI, consulta Chiedi ad AI per istruzioni su come utilizzarlo per rispondere a domande generali su ciò che sta accadendo nel feed della tua telecamera.
Utilizzando Claude
Per configurare Claude AI per rispondere alle domande su ciò che sta accadendo nel tuo feed video, vai su Impostazioni Server - Server AI e seleziona "Claude" sotto Chiedi ad AI.
- URL: Inserisci l'URL del servizio. Il valore predefinito è "https://api.anthropic.com/v1/messages".
- Chiave API di Claude: Dopo esserti registrato su Claude, visita la Pagina delle Chiavi API e crea una nuova chiave segreta. Copia e incolla questa chiave nel campo.
- Versione: Specifica la versione da utilizzare. Il valore predefinito è 2023-06-01. Questo potrebbe essere rimosso o modificato in futuro da Anthropic.
- Modello: Specifica il modello da utilizzare. Il valore predefinito al momento della scrittura è claude-3-sonnet-20240229.
- Token Massimi: Questo controlla la spesa massima di token per richiesta. Controlla i log su /logs.html se riscontri problemi poiché potrebbero essere legati alla spesa di token.
Una volta configurato Claude, consulta Chiedi ad AI per sapere come utilizzarlo per riconoscere scenari generali nel feed della tua telecamera.
Utilizzando Gemini
Per configurare Gemini per rispondere alle domande su cosa sta succedendo nel tuo feed video, vai su Impostazioni Server - Server AI e seleziona "Gemini" sotto Chiedi all'AI.
- URL: Inserisci l'URL del servizio. Il valore predefinito è "https://generativelanguage.googleapis.com".
- Chiave API Gemini: Dopo esserti registrato su Gemini, visita la Pagina delle Chiavi API e crea una nuova chiave segreta. Copia e incolla questa chiave nel campo.
- Versione: Specifica la versione da utilizzare. Il valore predefinito è v1beta. Questo potrebbe essere rimosso o modificato in futuro da Google.
- Modello: Specifica il modello da utilizzare. Il valore predefinito al momento della scrittura è gemini-1.5-flash.
- Token Massimi: Questo controlla la spesa massima di token per richiesta. Controlla i log su /logs.html se riscontri problemi poiché potrebbero essere legati alla spesa di token.
Una volta configurato Gemini, consulta Chiedi all'AI per sapere come utilizzarlo per riconoscere scenari generali nel feed della tua telecamera.
Utilizzare altri server LLM
Da v6.5.3.0+ puoi utilizzare i tuoi server LLM locali (come vLLM, Ollama e LM Studio) per descrivere le immagini catturate da Agent DVR dalle tue telecamere negli eventi di allerta e rispondere a domande su ciò che sta accadendo nei tuoi flussi video. Vedi AI Describe e Ask AI.
Per configurare un server AI locale, vai su Impostazioni del Server - Server AI e fai clic sul pulsante Configura accanto al LLM che desideri utilizzare (Ollama, vLLM o LM Studio).
- URL: Specifica l'endpoint in cui il tuo server LLM è in esecuzione. Gli URL predefiniti sono:
- Ollama:
http://localhost:11434/api/chat - vLLM:
http://localhost:8000/v1/chat/completions - LM Studio:
http://localhost:1234/v1/chat/completions
- Ollama:
- API Key: Se il tuo server LLM richiede autenticazione, inserisci qui la chiave API. La maggior parte dei server locali non richiede questo a meno che non sia specificamente configurato.
- Modello: Seleziona il modello capace di visione da utilizzare per l'analisi delle immagini. Devi aver già scaricato e caricato questo modello nel tuo server LLM. Le scelte popolari includono:
- Modelli LLaVA (visione a scopo generale)
- Qwen2-VL (alta prestazione)
- Llama 3.2 Vision (l'ultimo di Meta)
- Temperatura: Controlla la creatività rispetto all'accuratezza nelle risposte (0.0-1.0). Valori più bassi (0.3-0.4) producono descrizioni più fattuali e coerenti. Valori più alti (0.6-0.8) generano risposte più varie e creative. Raccomandato: 0.4 per l'analisi delle telecamere di sicurezza.
- Max Tokens: Numero massimo di parole/token nella risposta dell'AI. Valori più alti consentono descrizioni più dettagliate ma richiedono più tempo per essere generate. Raccomandato: 300-500 per analisi dettagliate delle immagini, 150-250 per descrizioni brevi.
- top_p: Controlla la diversità delle risposte limitando la selezione del vocabolario (0.0-1.0). Valori più bassi utilizzano parole più comuni, valori più alti consentono un vocabolario più vario. Raccomandato: 0.9 per un buon equilibrio tra accuratezza e linguaggio naturale.
- top_k: Limita il modello a scegliere tra le K parole più probabili successive. Valori più bassi (20-40) producono risposte più focalizzate, valori più alti (80-100) consentono maggiore varietà. Raccomandato: 50 per descrizioni affidabili delle immagini.
Utilizzando PlateRecognizer.com
Per configurare il riconoscimento della targa (ANPR o License Plate Recognition) in Agent DVR, vai su Impostazioni Server - Impostazioni AI e inserisci i dettagli sotto Plate Recognizer. Registrati per una prova gratuita su Plate Recognizer. Non è richiesta alcuna carta di credito.
- URL: Inserisci l'URL del servizio. Il valore predefinito è "https://api.platerecognizer.com/v1/plate-reader/", oppure utilizza il tuo server se stai ospitando la tua istanza.
- Token: Dopo esserti registrato su Plate Recognizer, visita la Pagina dell'Account e copia il Token API.
- Regioni: Lascia vuoto per il valore predefinito o inserisci un elenco CSV di regioni.
- Configurazione: Inserisci valori di configurazione aggiuntivi dalla documentazione se necessario.
Utilizzando DoubleTake
DoubleTake è una piattaforma open source che fornisce un'API unificata per l'elaborazione del riconoscimento facciale utilizzando:
- CompreFace
- Amazon Rekognition
- DeepStack
- CodeProject.AI Server
- Facebox
È necessario installare e configurare DoubleTake con le opzioni di riconoscimento facciale preferite.
Una volta configurato DoubleTake, apri Agent DVR e vai su Impostazioni Server - Server AI e fai clic sul pulsante Configura accanto a DoubleTake.
Inserisci l'URL del tuo server doubletake (ad es. http://localhost:3000/) e la tua password se impostata.
Fai clic su OK, quindi modifica una telecamera e vai su Riconoscimento Facciale. Imposta l'opzione Server AI su DoubleTake e configura il riconoscimento facciale secondo necessità.
Gestione dei Moduli AI
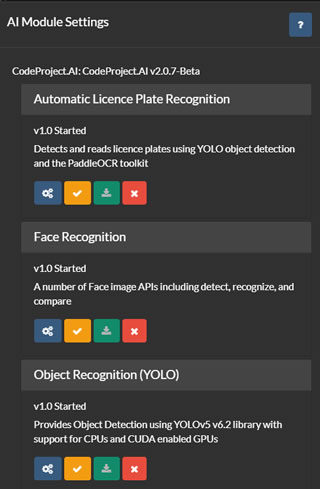
Nell'elenco dei server AI (sopra indicato), hai opzioni per configurare, testare, modificare e rimuovere i server AI. Clicca sul pulsante di configurazione per visualizzare i moduli disponibili o installati sul server selezionato.
Agent DVR recupera l'elenco dei moduli attuali dal tuo server e offre un'interfaccia utente per installare, disinstallare, configurare e testare ciascun modulo. Il supporto è fornito per tutti i moduli predefiniti di CodeProject.UI, anche se Agent DVR utilizza solo un sottoinsieme di questi.
Per utilizzare ALPR (Riconoscimento Automatico delle Targhe), Super Risoluzione o Riconoscimento Facciale in Agent DVR, dovrai installare il rispettivo modulo da questa pagina. Di solito, le impostazioni predefinite sono sufficienti per questi moduli, ma puoi configurarli cliccando sull'icona sotto ciascun modulo.