AI (人工知能): 設定 (せってい)
ローカルオブジェクト認識
Agent DVRは、AIモデルファイル(.onnx)を使用したライブリアルタイムのオブジェクト認識をサポートしています。この機能を使用するには、ライセンス(またはアクティブなサブスクリプション)が必要です。外部AIサーバーを使用するための設定については、AIサーバーを参照してください。
始めるには、カメラを編集し、オブジェクト認識タブに移動します。上部でAIサーバーを選択します。デフォルトは内部で、これはAgent DVRの内蔵AIです。AIサーバーを使用したい場合は、サーバー設定 - AI設定 - AIサーバーで追加し、ここで選択します。
以下の詳細は、Agent DVRをその高速な内蔵AIで設定するためのものです。例えば、Ultralytics YOLOモデルなど、他のモデルも追加できます。
- モデル: 使用したいAIモデルを選択します。Agentは必要に応じて内蔵モデルを自動的にダウンロードします。Tinyモデルは、低スペックのハードウェアや多数のカメラに適しています。Mediumモデルは、より高い精度を提供しますが、より多くの処理能力を使用します。
- モード: AIがビデオのフレームを処理するタイミングを選択します。Intervalを選択すると、Agentは下の処理レートフィールドを使用して、ビデオフィードを継続的に分析します。
- オーバーレイ: ライブビデオにリアルタイムの結果を描画するにはチェックを入れます。これは信頼度の調整に最適です。
- ぼかし: 認識されたオブジェクト(例えば、人)をぼかすにはチェックを入れます。
- GPUを使用: CPUの代わりにGPUを使用するにはチェックを入れます。
- 処理レート: これはモードがIntervalのときのみ使用され、フレームがモデルに送信されるレートを制御します。1秒間に1フレームの場合は1、1秒間に20フレームの場合は20、10秒ごとに1フレームの場合は0.1を入力します。
- 信頼度: これはモデルからの結果をフィルタリングします。誤検知を減らすためにこれを高く調整しますが、オブジェクトを見逃す可能性もあることに注意してください。
- コーナーをチェック: 詳細についてはコーナーのチェックを参照してください。
- 検出: AIに検出させたいオブジェクトを指定します。ここでのオプションのリストはモデルの設定から来ています。
- 静的オブジェクトを無視: 同じ場所で繰り返し見つかるオブジェクトを無視します。
- 許容範囲: これはオブジェクトが静的でないとフラグ付けされる前にどれだけ移動できるかを制御します。
カスタムモデル
独自のモデルをAIに追加するには、モデルファイル(.onnx)をAgentのモデルフォルダーにコピーし、モデルの追加を参照してください。
アクション
オブジェクト認識は、AI: オブジェクトが見つかりましたおよびAI: オブジェクトが見つかりませんでしたイベントを生成し、アクションで使用します。
写真
写真に関する情報は、写真を参照してください。
Ultralytics YOLOモデルをONNXに変換する
Agent DVRは、物体認識のためにONNXモデルファイルをサポートしています。事前学習済みモデルをダウンロードし、数ステップでONNX形式に変換できます。
以下の例では、Ultralyticsを介してYOLO26sモデルを使用しています。YOLO26sは、良好な速度/精度のトレードオフを持つ小型の汎用モデルです。
前提条件
- Python 3.10以上
- PATHにpipが利用可能
- インターネット接続
- 約1〜2GBの空きディスクスペース
ステップ1 – Ultralyticsのインストール
pip install ultralyticsステップ2 – YOLO26sモデルのダウンロード
Ultralyticsは、初回使用時に自動的に事前学習済みの重みをダウンロードします:
yolo detect predict model=yolo26s.pt source=https://ultralytics.com/images/bus.jpgステップ3 – ONNXへの変換
ダウンロードが完了したら、モデルをONNX形式にエクスポートします:
yolo export model=yolo26s.pt format=onnx opset=12 simplify=TruePythonの代替手段
from ultralytics import YOLO
model = YOLO("yolo26s.pt")
model.export(format="onnx", opset=12, simplify=True)ステップ4 – ONNXファイルの場所を特定
エクスポートされた
yolo26s.onnxruns/exportステップ5 – Agent DVRにコピー
ONNXファイルをAgent DVRのONNXモデルフォルダ(Agentサーバー上)に移動します。例えば:
Agent\Media\Models\ONNX\ステップ6 – Agent DVRにモデルを追加
- サーバー設定 > AI設定 > AIモデルに移動します。
- 設定をクリックし、新しいモデルを追加します。
-
名前(例:
)を入力し、ドロップダウンからyolo26s
ファイルを選択します。.onnx - 残りのオプションはデフォルトのままにし、OKをクリックします。
- カメラを編集し、物体認識タブを開き、サーバーを内部に設定し、新しいモデルを選択します。
ローカル顔認識
Agent DVRは、AIを使用したライブリアルタイムの顔認識をサポートしています。この機能を使用するには、ライセンス(または有効なサブスクリプション)が必要です。外部AIサーバーを使用するための設定については、AIサーバーを参照してください。
始めるには、カメラを編集し、顔認識タブに移動します。上部でAIサーバーを選択します。デフォルトは内部で、これはAgent DVRの内蔵AIです。AIサーバーを使用する場合は、サーバー設定 - AI設定 - AIサーバーで追加し、ここで選択します。
以下の詳細は、Agent DVRをその高速内蔵AIで設定するためのものです。
- モード: AIがビデオのフレームを処理するタイミングを選択します。間隔を選択すると、Agentは下の処理レートフィールドを使用して、ビデオフィードを継続的に分析します。
- オーバーレイ: ライブビデオにリアルタイムの結果を描画するにはチェックを入れます。これは信頼度の調整に最適です。
- ぼかし: 顔をぼかすにはこれにチェックを入れます。
- GPUを使用: CPUの代わりにGPUを使用するにはこれにチェックを入れます。
- 処理レート: これはモードが間隔のときのみ使用されます - フレームがモデルに送信されるレートを制御します。1秒間に1フレームの場合は1、1秒間に20フレームの場合は20、10秒ごとに1フレームの場合は0.1を入力します。
- 信頼度: これはモデルからの結果をフィルタリングします。誤検出を減らすためにこれを高く調整しますが、人を見逃す可能性もあることに注意してください。
- コーナーをチェック: 詳細についてはコーナーのチェックを参照してください。
認識する顔
認識したい人の写真をアップロードするには「顔を編集」をクリックします。同じ人の複数の写真をアップロードすることで結果を改善できます。ファイルシステムから画像をアップロードするか、内蔵ウェブカメラを使用して写真をキャプチャできます(SSLまたはlocalhostが必要です)。
アクション
顔認識は、AI: 顔認識済みおよびAI: 顔未認識イベントを生成し、アクションで使用します。
写真
写真に関する情報は、写真を参照してください。
ローカルナンバープレート認識
Agent DVRはライブリアルタイムナンバープレート認識をサポートしています。この機能を使用するには、ライセンス(またはアクティブなサブスクリプション)が必要です。外部AIサーバーを使用するための設定については、AIサーバーを参照してください。
始めるには、カメラを編集し、LPRタブに移動します。上部でAIサーバーを選択します。デフォルトはInternalで、これはAgent DVRの内蔵AIです。AIサーバーを使用する場合は、サーバー設定 - AI設定 - AIサーバーで追加し、ここで選択してください。
以下の詳細は、Agent DVRをその高速内蔵AIで設定するためのものです。
- モード: AIがビデオのフレームを処理するタイミングを選択します。Intervalを選択すると、Agentは下の処理レートフィールドを使用してビデオフィードを継続的に分析します。
- オーバーレイ: ライブビデオにリアルタイムの結果を描画するにはチェックを入れます。これは信頼度の調整に最適です。
- ぼかし: 検出されたナンバープレートをぼかすにはチェックを入れます。
- GPUを使用: CPUの代わりにGPUを使用するにはチェックを入れます。これは現在、GPUドライバーとランタイムサポートのためにWindowsまたはmacOSでのみ機能します。Linuxは現在CPUにフォールバックします。
- 処理レート: これはモードがIntervalのときのみ使用され、フレームがモデルに送信されるレートを制御します。1秒あたり1フレームの場合は1、1秒あたり20フレームの場合は20、10秒ごとに1フレームの場合は0.1を入力します。
- 信頼度: これはモデルからの結果をフィルタリングします。誤検出を減らすためにこれを高く調整しますが、オブジェクトを見逃す可能性もあることに注意してください。
- コーナーをチェック: 詳細についてはコーナーのチェックを参照してください。
探すべきナンバープレート
- ナンバープレート: カンマ区切りのナンバープレートのリストまたはナンバープレートを含むCSVファイルのURLを入力します。Agent DVRはこれらのナンバープレートに対してナンバープレート認識済みおよびナンバープレート未認識イベントを生成し、アクションをトリガーできます。
- リロード間隔: URLからプレートリストを再読み込みする頻度を設定します。
- 正規化: 一般的に誤認識されるプレートを調整してマッチングを改善します。
アクション
オブジェクト認識は、AI: ナンバープレート認識済みおよびAI: ナンバープレート未認識イベントを生成し、アクションで使用します。
写真
写真に関する情報は、写真を参照してください。
AIアラートフィルタリング
Agent DVRでアラートフィルタリングを設定するには、以下の手順に従ってください:
- モーションディテクターを設定して有効にします。最小限のCPU使用量のために、シンプルディテクターを使用してください。監視したいエリアをカバーするために、少なくとも1つのゾーンが定義されていることを確認してください。
- アラートタブで、モードをアクションのみに設定し、アラートを有効にします。
- 録画タブで、モードをアラートに設定します(録画を希望する場合)。
- オブジェクト認識タブでオブジェクト認識を有効にします。モードをモーション検出に設定し、モデルを選択して検索をクリックし、人物、犬、車などの検出対象を選択します。
- タブメニューのアクションに移動し、イベントAI: オブジェクト検出のアクションを追加します。
オブジェクトを検出する場所を指定するためにゾーンを選択します。例えば、ドライブウェイと道路の異なるゾーンを設定します。ドライブウェイゾーンを選択すると、そこに車が検出された場合のみアラートがトリガーされます。
タスクの下で、追加をクリックしてアラートタスクを作成します。確認のためにOKを2回クリックします。
Agent DVRは、動体検知時にAIオブジェクト認識を処理します。指定されたオブジェクトが選択されたゾーン内で検出されると、アクションをトリガーしてアラートを発生させます。ゾーンが選択されていない場合、すべてのゾーンに対してアラートが発生します。
LPR認識、顔認識、または音声認識についても同様にアラートフィルターを設定してください。
動体検知トリガーなしで常時AIオブジェクト認識を行うには、オブジェクト認識のモードをインターバルに設定します。ハードウェアリソースへの影響を監視し、必要に応じて調整してください。
異なるゾーン内の異なるオブジェクトに対して複数のアクションを構成できます。検出されたオブジェクトを参照するために、アクション内で{AI}タグを使用してください。
AIフィルターのトラブルシューティング
AIが録画を効果的にフィルタリングしていない場合は、次のことを考慮してください:
- [Available options]のいずれかに一致するようにFind設定を確認してください。
- Agentの左上にあるマスターアラートスイッチが閉じた南京錠を表示していることを確認してください。これはアクティブなアラートを示しています。
- 録画モードがAlertに設定されていることを確認してください。Detectではありません。
- アラートモードがActions Onlyに設定されていることを確認してください。
- Object Recognitionの下でConfidenceレベルを下げてみてください。
- エラーメッセージが表示されている場合は、/logs.htmlをチェックしてください。これはサーバーの問題やネットワークのブロックを示している可能性があります。
- AIサーバーのパフォーマンスを監視し、システムの過負荷やタイムアウトが発生していないことを確認してください。
- AIがすべてのオブジェクトクラスを検出する場合、GPUの問題を示している可能性があります。GPUドライバーを確認するか、CPUベースのAIモジュールに切り替えてください。
AIオブジェクト認識
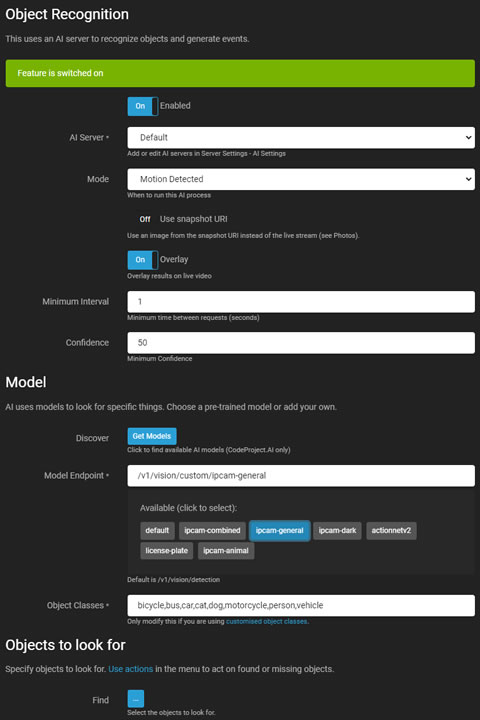
Agent DVRのオブジェクト認識は、ローカルAIまたはAIサーバー(CodeProject.AI推奨)を使用して、ビデオフィード内の特定のオブジェクトを認識し、イベントを生成したり、アラートを発生させたり、動体アラートのフィルターとして機能します。
- 有効: AIプロセスを有効または無効にするためのトグル。
- AIサーバー: 設定済みのサーバーから選択するか、デフォルトオプションを使用します。
- モード: AIプロセスのトリガーを選択します。これをNoneに設定し、triggerObjectを呼び出すことでAPI経由でトリガーします。
- モーションパススルー: AIサーバーがダウンしてアラートをフィルタリングしている場合、フィルタリングなしでアラートを通過させることができます。
- スナップショットURIを使用: 現在のライブストリームフレームの代わりにカメラからの高解像度フレームを使用します。
- リサイズモード: AIサーバーに送信する前に画像のサイズを変更して負荷を軽減し、応答時間を改善します。
- オーバーレイ: ライブビデオストリーム上にAIの結果を表示します。
- 色: オーバーレイの色。この設定は、すべてのAI機能のオーバーレイの色を制御します。
- 最小間隔: サーバーリクエスト間の最小時間を設定します。
- 信頼度: オブジェクトを認識するための最小信頼度レベルを設定します。
- コーナーチェック: 詳細についてはコーナーチェックを参照してください。
モデル
- 発見: サーバーからインストールされたモデルを取得します(CodeProject.AIに特有)。
- モデルエンドポイント: 利用可能なモデルから選択するか、デフォルトのエンドポイントを使用します。
- オブジェクトクラス: 関連するクラスで自動的に入力されるか、手動で入力されます。
- 検索: AIが検出するオブジェクトを指定します。
- 静的オブジェクトを無視: 同じ場所で繰り返し見つかるオブジェクトを無視します。
カスタムモデル
CodeProject.AIにカスタムモデルを追加するには、モデルファイルを指定されたディレクトリにコピーします。発見ボタンを介してアクセスしますが、オブジェクトリストはオブジェクトクラスに手動で追加してください。
オブジェクト認識モジュールの設定を編集することで、モデルストレージのディレクトリを変更できます。
アクション
オブジェクト認識は、AI: オブジェクト発見およびAI: オブジェクト未発見イベントを生成し、アクションで使用します。
写真
写真に関する情報は、写真を参照してください。
AIに尋ねる
Agent DVRは、カメラの画像に関する人間が読める質問に答えるためにAIサーバー(OpenAI / Claudeなど)を使用します。これにより、イベントを生成したり、アラートを発生させたり、動きのアラートにフィルターをかけることができます。Server Settings - AI Servers - Ask AIで設定を完了する必要があります。
リクエストが送信されるタイミングを確認するには、ローカルサーバーの/logs.htmlでログを確認できます。Server Settings - Logging - Log LevelをInfoに設定してください。
- Enabled: AIプロセスを有効または無効に切り替えます。
- Provider: 画像を処理するために使用するAIプロバイダーを選択します。プロバイダーはサーバー設定 - AIサーバーで構成する必要があります。デフォルトを選択すると、最初に構成されたプロバイダーが使用されます。
- Mode: AIプロセスのトリガーを選択します。これをNoneに設定し、triggerAskAIを呼び出すことで、API経由でトリガーを設定できます。
- Motion Pass-through: AIサーバーがダウンしてアラートをフィルタリングしている場合、このオプションを使用すると、フィルタリングなしでアラートを通過させることができます。
- Use Snapshot URI: 現在のライブストリームフレームの代わりに、カメラから高解像度のフレームを使用します。
- Resize Mode: AIサーバーに送信する前に画像をリサイズして、負荷を軽減し応答時間を改善します。
- Overlay: ライブビデオストリームにAIの結果を表示します。
- Minimum Interval: サーバーリクエスト間の最小時間を設定します。
AI メッセージング
- メッセージ: ここにAIへの質問を入力してください。いくつかの例:
- この画像に火災が見られる場合は FIRE と返信してください。ソファに座っている犬が見られる場合は DOG と返信してください。ドアが開いている場合は DOOR と返信してください。複数の条件が満たされた場合は、それらを , で区切ってください。
- ベンチの上の機械のライトが赤い場合は ALERT と返信してください。
- 警察車両がドライブウェイに停まっている場合は POLICE と返信してください。
- 床に郵便物や荷物がある場合は MAIL と返信してください。
- 誰かが家に侵入したように見える場合は BREAKIN と返信してください。
- 検索: AIに応答するよう指示したタグを入力してください。例: FIRE, DOG, DOOR
- 繰り返し無し: 前回のAIへの呼び出しで返されたタグを無視してください。
上記のように、メッセージで複数の条件を満たすよう要求し、各結果を処理するアクションを設定できます。
アクション
シーン認識は、Ask AI: Positive Result イベントを生成し、アクション で使用します。
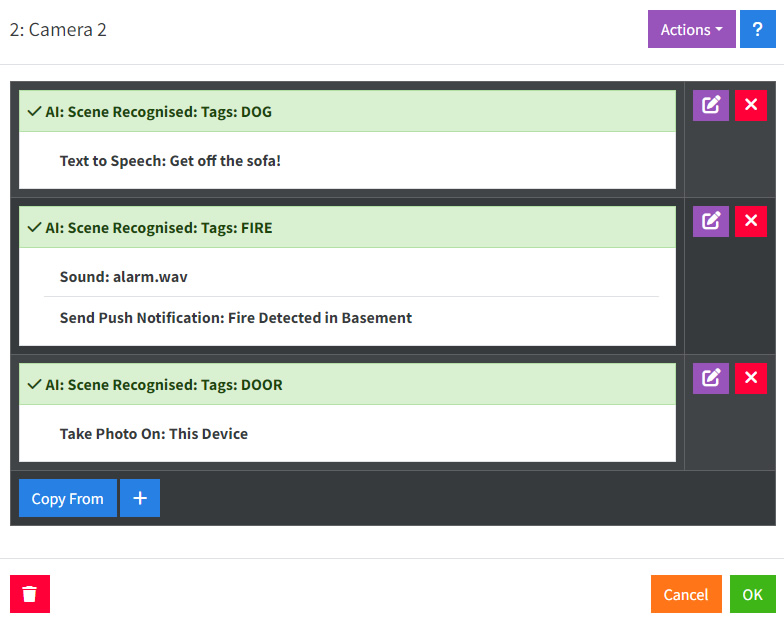
写真
写真に関する情報は、写真 を参照してください。AIはまだ画像内の物体の位置に関する空間データを返さないため、クロップや静的検出は現在機能していません。
AI写真
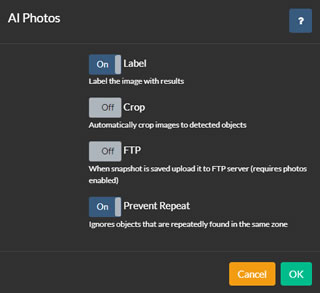
AIプロセスは、オブジェクトが認識されたときに写真をキャプチャすることができ、保存、切り抜き、FTPアップロードなどのオプションが提供されます。
これを設定するには、カメラの編集時に各AI設定タブの下部にある写真オプションに移動します。写真を有効にし、設定をクリックします。
- ラベル: Agentは画像上にボックスを重ねて検出されたオブジェクトにラベルを付けます。
- 切り抜き: Agentは画像を各検出領域に切り抜き、各領域ごとに複数の画像を保存します。
- FTP: 保存された画像をカメラに設定されたFTPサーバーにアップロードします。
- 重複防止: Agentは同じオブジェクトの複数のコピーを保存せず、それがモーションゾーンを離れるまで待機します。
Ask AI: 説明
v5.8.2.0+から、Agent DVRがカメラからキャプチャした画像をアラートイベントで説明するためにAIを使用できます。この説明は、UI内のアラートと一緒に保存されます。これを設定するには、カメラ用にAsk AIを構成し、Describeの下にあるオプションを表示してください。
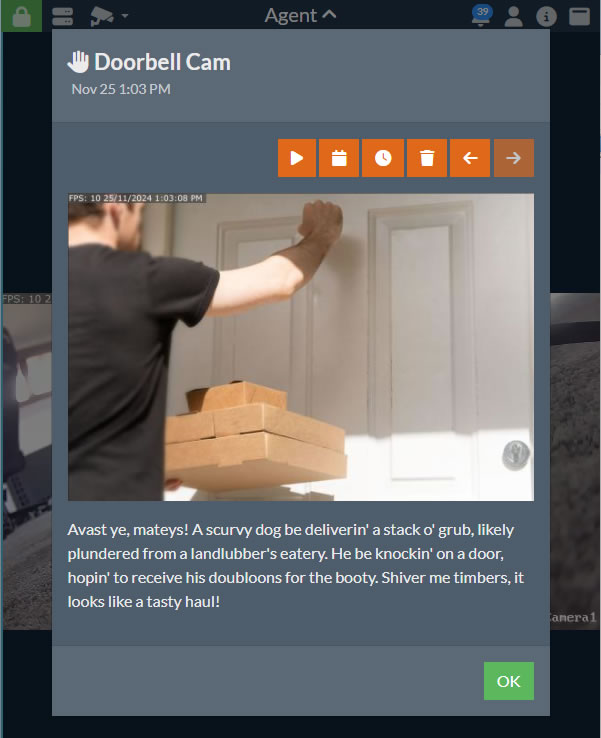
- Prompt: 画像と一緒にAIサーバーに送信されるプロンプトを入力します。デフォルトは「この画像で何が起こっているかを短い文章で説明してください」となっています。ただし、「海賊の言葉で何が起こっているかを説明してください」といった楽しいプロンプトも使用できます。上記の画像で使用したものです。
- 次に、アラートタブに移動し、Describeオプションをチェックしてください。
Ask AIが有効になっていることを確認してください。アラート画像の説明のみを行いたい場合は、ModeをNoneに設定してください。
画像に注釈を付けたら、ActionsシステムにAI: Describe Response Receivedを統合できます。このアクションから他の統合に対して{MESSAGE}と{AIJSON}を使用できます。
LPRまたはALPR
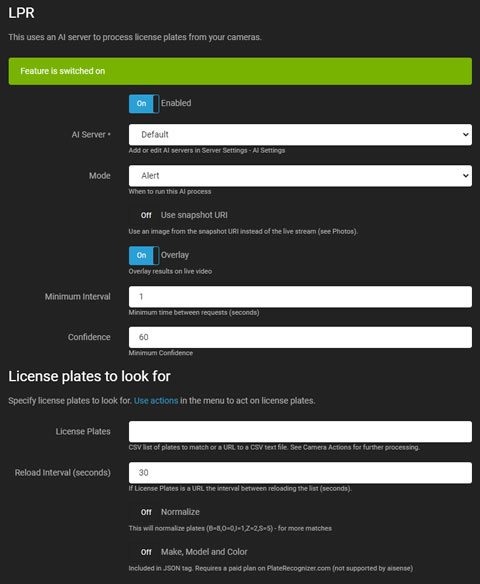
LPR(ナンバープレート認識、ALPR/ANPRとも呼ばれます)は、AIサーバーを利用して、ビデオフィード内の車両のナンバープレートを認識し、読み取ります。イベントを生成し、アラートを上げたり、動体検知アラートのフィルターとして機能します。
- 有効: AIプロセスを有効または無効にするためのトグル。
- AIサーバー: 設定したサーバーから選択するか、デフォルトオプションを使用します。Agent DVRは、CodeProject.AI、PlateRecognizer.com、Gemini、またはOpenAI互換のビジョンLLM(vLLM、Ollama、LM Studioなど)を介してLPRをサポートしています。
- モード: AIプロセスのトリガーを選択します。これをNoneに設定し、triggerLPRを呼び出すことで、API経由のみでトリガーします。
- スナップショットURIを使用: 現在のライブストリームフレームの代わりに、カメラからの高解像度フレームを選択します。
- オーバーレイ: AIの結果をライブビデオストリームにオーバーレイします。
- 最小間隔: サーバーリクエスト間の最小時間を設定して負荷を減らします。
- 信頼度: ナンバープレートを認識するための最小信頼度レベルを定義します。
- コーナーをチェック: 詳細についてはコーナーのチェックを参照してください。
- ナンバープレート: カンマ区切りのナンバープレートのリストまたはナンバープレートを含むCSVファイルのURLを入力します。Agent DVRは、これらのナンバープレートに対してナンバープレート認識済みおよびナンバープレート未認識イベントを生成し、アクションをトリガーできます。
- リロード間隔: URLからナンバープレートリストを再読み込みする頻度を設定します。
- 正規化: 一般的に誤認識されるナンバープレートを調整してマッチングを改善します。
- メーカー、モデル、色: これらの機能をサポートするPlateRecognizer.comの有料プランを使用している場合にのみ有効にします。無料プランには含まれていません。詳細はAgent DVR Actionsの{AIJSON}に含まれます。
アクション
LPRは、AI: ナンバープレート認識済みおよびAI: ナンバープレート未認識イベントを生成し、アクションで使用します。
写真
写真に関する情報は、写真を参照してください。
ALPR-Databaseの使用
ALPR-Database.comとの統合を設定して、ナンバープレートを保存できます。手順については、Agent DVRとALPR-Databaseを参照してください。
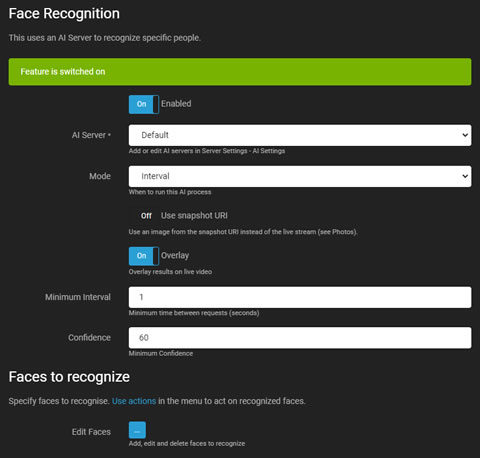
AI顔認識
顔認識は、特定の顔をビデオフィードで認識するためにAIサーバー(推奨: CodeProject.AI)を利用します。イベントを生成したり、アラートを上げたり、動体アラートのフィルターとして機能したりします。顔はカメラを使用して追加、編集、または削除することができ、画像をアップロードすることも可能です。このタブの顔の編集を参照してください。
- 有効: AIプロセスを有効または無効にするためのトグル。
- AIサーバー: 設定済みのサーバーから選択するか、デフォルトオプションを使用します。
- モード: AIプロセスのトリガーを選択します。これをNoneに設定し、triggerFaceを呼び出すことでAPI経由のみでトリガーします。
- スナップショットURIを使用: 現在のライブストリームフレームの代わりにカメラからの高解像度フレームを選択します。
- オーバーレイ: AIの結果をライブビデオストリームにオーバーレイします。
- 最小間隔: サーバーリクエスト間の最小時間を設定して負荷を軽減します。
- 信頼度: 顔を認識するための最小信頼度レベルを定義します。
- コーナーの確認: 詳細についてはコーナーの確認を参照してください。
- 顔の編集: 認識のためにサーバーデータベースに画像をアップロードします。各画像には1つの顔のみが明確に表示されていることを確認してください。
アクション
顔認識は、AI: 顔認識済みおよびAI: 顔未認識イベントを生成し、アクションで使用します。
写真
写真に関する情報は写真を参照してください。
AIオーディオ認識
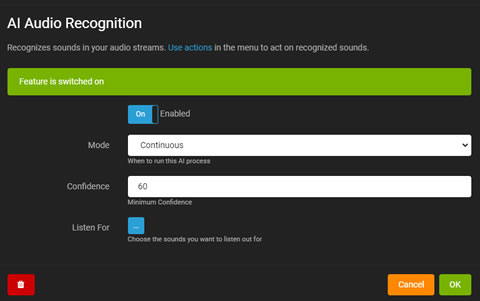
Agent DVRのAIベースのオーディオ認識は、マイクやオーディオストリームから認識された音に応答します。これを設定するには、サーバー設定 - データ - AIオーディオモデル(iSpyConnect.comのアカウントが必要)からモデルファイルをダウンロードしてください。
オーディオ認識を設定するには、マイクの設定を編集する必要があります。オーディオストリームを持つカメラがある場合、カメラの編集を行い、オーディオタブを選択し、「設定」をクリックしてオーディオ設定にアクセスできます。
- 有効化: AIプロセスを有効または無効に切り替えます。
- モード: AIプロセスのトリガーを選択します。
- 信頼度: 音の認識のための最小信頼度レベルを設定します。
- オーバーレイ: ライブオーディオ可視化にAIの結果を表示します。
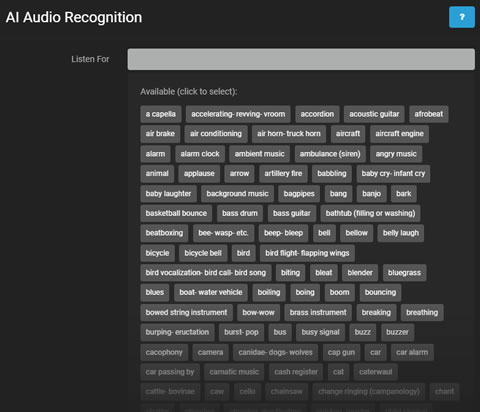
- 検出対象: AIが検出する特定の音を選択します。
検出対象をクリックすると、検出可能な音が表示されます。必要に応じて音を選択してください。
アクション AI: 音が認識された場合をクリックして、音が識別されたときにタスクを実行します。
オーディオ認識は、カメラと同様に、アラートのフィルタリングにも使用できます。
AI イベントにアクションを追加する
Agent DVRはAIプロセスを通じてイベントを生成し、それによってアクションがトリガーされます。たとえば、オブジェクト認識は「オブジェクトが見つかりました」および「オブジェクトが見つかりませんでした」というイベントを生成します。Agent内の各AIシステムはユニークなイベントを生成します。
これらのイベントは、アラートの発生、オブジェクトラベル付きのURLの呼び出し、プログラムの実行、またはMQTTサーバーへのメッセージの公開など、さまざまなアクションをトリガーすることができます。アクション内では、ラベルには{AI}タグ、CodeProject.AIからのフルJSONレスポンスには{AIJSON}タグを使用してください。